
멀티모달을 활용한 자율주행 세미나
안녕하세요! 원클릭 에이아이에서 세미나를 담당하고 있는 오승영 입니다! 오늘은 기존의 자율주행 강의를 넘어서 최근에 많은 빅테크에서 활용되고 있는 멀티모달 자율주행 세미나를 충북대, 청주대 학생들을 대상으로 진행했습니다. 세미나지만, 실습도 함께 진행하는 학생 참여형 세션로 진행되었고, 이번 세미나에서는 저희 자율주행 키트를 갖고, 단순히 이미지만을 갖고 자율주행을 하는 것이 아니라, 이미지와 텍스트를 모두 입력으로 받아 차량의 제어값을 내보내주도록 진행했습니다.
멀티모달이 뭐야, 이게 왜 필요한가?
혹시 멀티모델 아냐? 라고 헷갈려 하실 수도 있는데, 멀티모달이 맞습니다.
멀티모달(Multi-Modal) 이란, 하나의 모델이 두 가지 이상의 서로 다른 형태의 데이터(Modalities)를 동시에 이해하고 처리하는 기술을 의미합니다.
예를 들어,
- 이미지(카메라 영상)
- 텍스트(도로 상황 설명, 목적지, 제약 조건 등)
- 센서 데이터(LiDAR, GPS 등)
반면 ‘멀티 모델(Multi-model)’이라는 말은, 하나의 모델이 여러 입력을 처리하는 것이 아니라, 말 그대로 ‘여러 개의 모델을 함께 사용하는 방식’을 의미합니다. 가장 대표적인 예시는 앙상블(Ensemble) 입니다. 예를 들어 여러 모델이 같은 입력을 처리하고, 그 출력을 평균 내거나 투표를 통해 최종 결정을 내리는 방식은 멀티-모델 시스템(또는 앙상블 모델) 이라고 할 수 있습니다.
즉, 멀티모달은 “하나의 모델이 다양한 입력을 처리하는 것”, 멀티모델은 “여러 모델이 힘을 합쳐 하나의 결과를 내는 것”입니다.
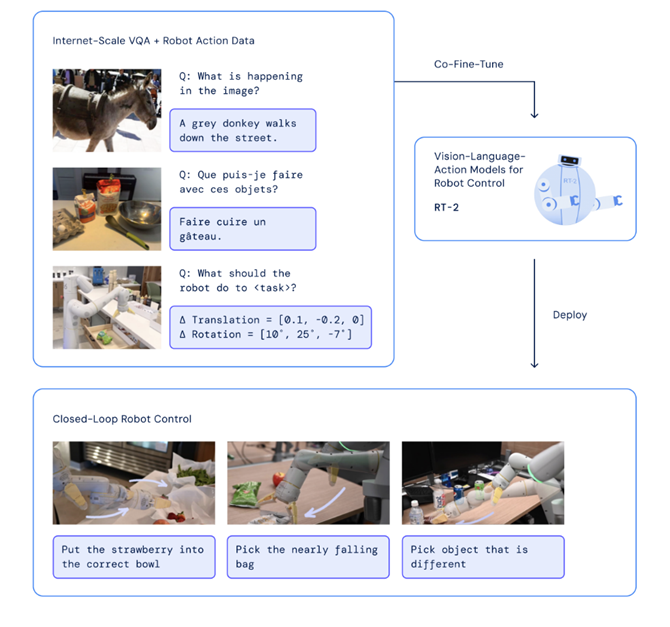
< 구글의 RT-2모델, 따로 학습하지 않더라도 사용자의 지시사항을 이해하고 문제를 해결 >

< 멀티모달 아키텍쳐: 이미지도 텍스트와 함께 임베딩 값을 받고, 제어 값을 출력해준다. >
기존 방식(모듈형) vs End-to-End
이렇게 서로 성격이 다른 정보들을 한 번에 받아들이고, 이를 종합적으로 판단하여 결정을 내릴 수 있도록 하는 것이죠. 최근에는 Waymo, Google, Tesla 등 대부분의 자율주행 및 로봇 회사들이 멀티모달 기반의 모델을 적극적으로 연구하고 있으며, 단순히 “보는 것”을 넘어 “이해하고 판단하는 AI”로 발전하고 있습니다.
기존에는, 센서 입력을 받는 부분부터, 제어 값을 내주는데 까지 여러 모델을 거치면서 "모듈화" 된 방식으로 자율주행이 되었는데, 이제는 이 "모듈화"된 구간을 없애고, 하나의 모델로 통합하는 end-to-end 방식을 도입하고 있습니다.
모듈화 방식의 장점은, 각각의 모듈에서 나오는 출력을 직접 확인하고 모듈별로 디버깅이 가능해서, 모듈별로 수정이나, 변경이 용이합니다. 그러니, 최종 제어값에 문제가 있다면, 각각의 모듈의 출력값을 확인해서 어떠한 모듈에서 이상한 값이 나왔는지 확인하고, 이를 쉽게 수정할 수 있습니다. 그런데, 단점으로는 각각의 모듈에서 나오는 출력값이, 다음모듈로 넘어갈때, 압축이 되어서 넘어가게 됩니다.
예를들어, yolo 모델을 사용했다고 가정하면, 이미지 데이터가 모델의 입력으로 들어가고, 출력으로는 이미지 내 객체의 위치가 출력으로 나와서 다음 모듈로 들어가게 됩니다. 이 과정에서 이미지 전체 정보(픽셀 데이터)가 ‘객체의 위치’라는 일부 정보로 압축되며, 이때 사라지는 정보가 생깁니다. 다음 모듈은 전체 데이터를 확인하지 못하고 이렇게 압축된 데이터만 확인할 수 있게 됩니다. 그럼 다음 모듈은 일부 소실 된 데이터를 갖고 다음 연산을 하게 되는 것이죠.
End-to-end 방식의 장점은 그럼 무엇일까요. 입력과 출력이 하나의 모듈로 되어있기 때문에, 중간에 데이터가 압축되는 과정이 없고, 단일 손실 함수로 모델을 학습하게 됩니다. 즉, 각각의 모듈이 일을 잘 했는지 파악하기 보다, 최종 결과가 한번에 잘 나오도록 학습을 진행하기 때문에, 목적에 맞게 더 잘 학습이 됩니다. 다만, 결과가 이상할 경우, 모듈화가 안되어있다보니, 디버깅이 어렵다는 단점이 있습니다.
정리하면, 멀티모달 + End-to-End는 ‘더 많이 보고, 더 깊게 이해하고, 더 자연스럽게 운전하는 AI’로 발전시키는 핵심 기술입니다.
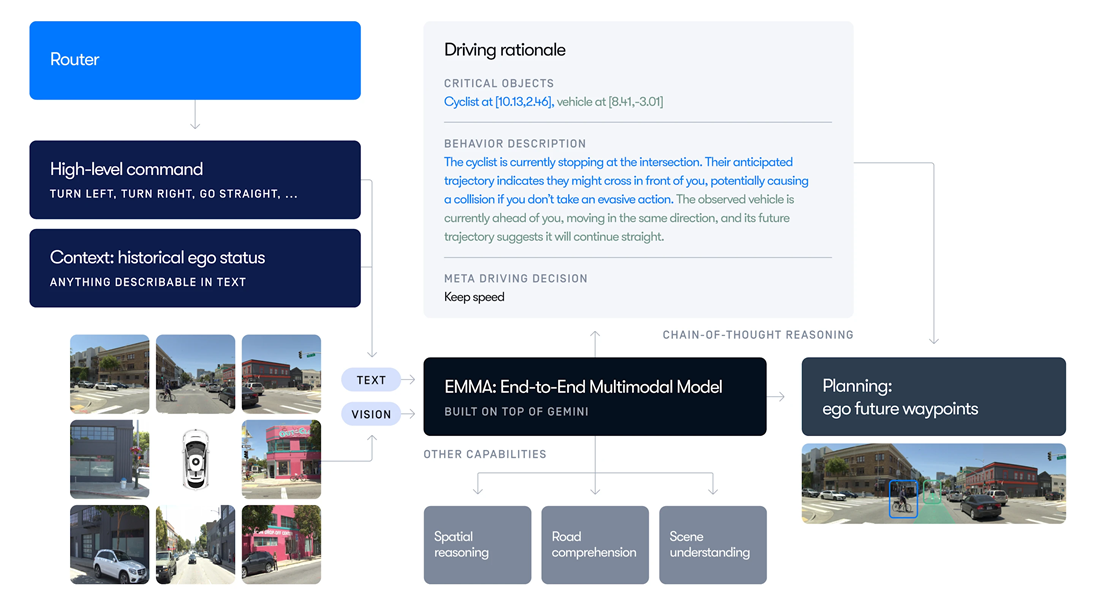
< Weymo, EMMA(End-to-end Multimodal Model for Autonomous driving) >
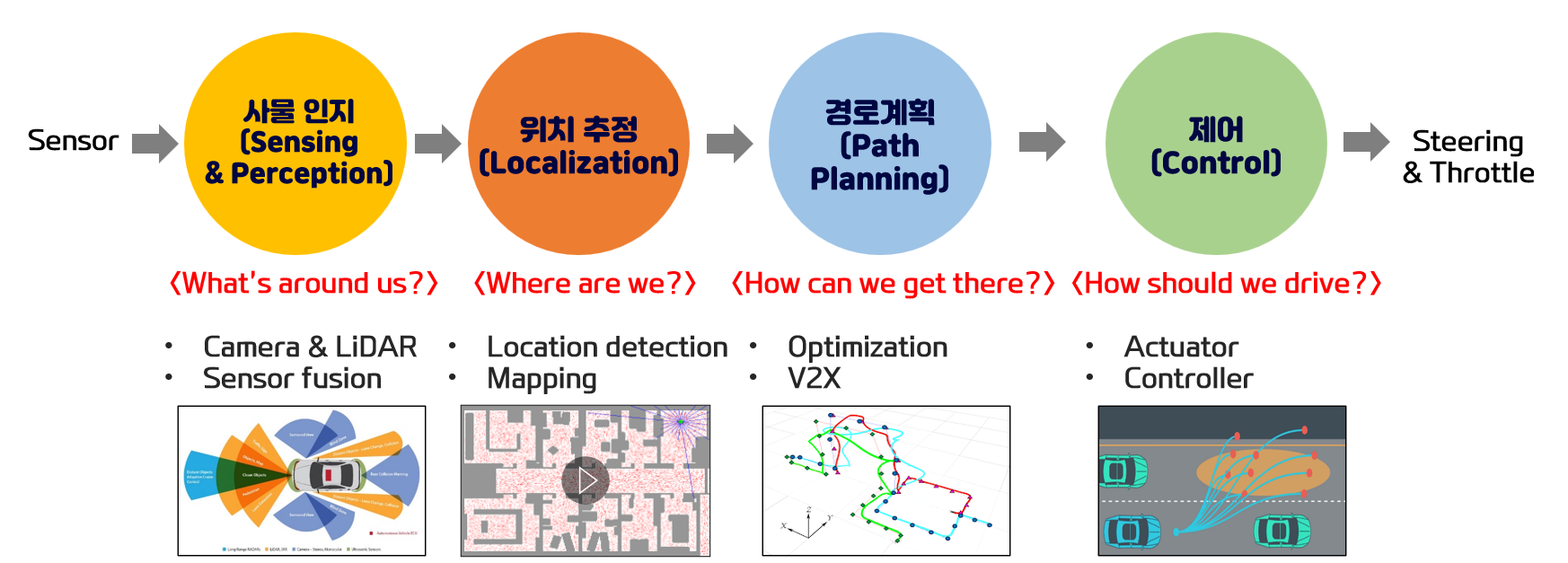
< 기존 자율주행: 모듈화 방식 >
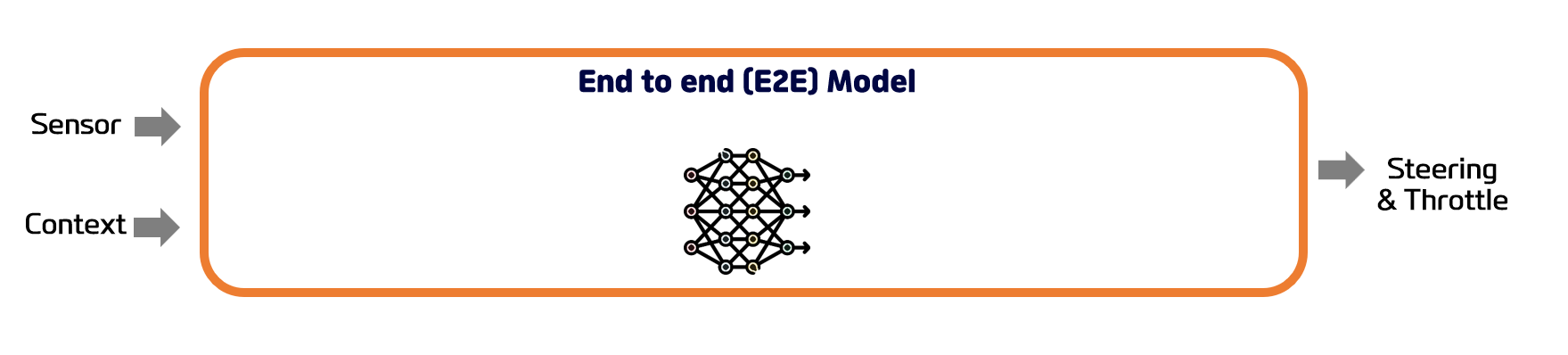
< End to end 자율주행 방식 >
사용한 모델
본 세미나 과정에서는 원클릭 에이아이에서 만든 In-house 모델을 사용했습니다. 해당 모델은 소형 언어모델(Small language Model)과 이미지 모델인 CNN을 결합한 방식으로 만들어진 모델인데요, 언어모델의 첫번째 혹은 마지막 토큰이 이미지 모델에서 나온 임베딩 값이 되는 모델입니다. 해당 모델은 텐서플로우로 만들어져서 다른 하드웨어에서도 쉽게 접목이 가능한 모델입니다. 그럼에도 SLM의 특성상 보편화 특성(Generalization)이 부족한 것이 단점으로 지목되고 있습니다. 하지만, 학생들이 직접 취득한 데이터를 활용하여 올바르게 학습한다면 충분히 Loss가 낮은 잘 동작하는 모델로 탈바꿈 하게 됩니다. 이런식으로 저지연 모델을 구성해서 자율주행 하드웨어에 탑재하는 방식으로 진행했습니다.

세미나 진행 과정
예를 들어 이번 주행에서 입력되는 텍스트는 예를들면, "횡단보도 보이면 일시정지 해줘"나, "횡단보도 무시하고 직진해줘"와 같이, 어떤 특정한 상황에 맞닥드렸을때, 어떻게 주행할지를 텍스트를 통해 학습하게 됩니다. 따라서, 다양한 상황에서, 더 상황에 맞는 주행을 할 수 있게 됩니다. 즉, 학생들은 단순한 모델 사용이 아니라, 최신 자율주행 업체들이 실제로 사용하는 학습 방식을 직접 구현하고 확인할 수 있었습니다.
여기서 사용된 멀티모달은, 이미지 데이터를 하나의 임베딩 값으로 만들어서 텍스트 임베딩 값의 가장 처음에 추가합니다. 즉, 첫번째 임베딩 값이 텍스트가 아니라 이미지가 되고 나머지 임베딩 값은 텍스트로 채우게 됩니다. Transformer 모델을 사용해서 학습하고 이를 활용하여 자율주행까지 함께 진행했습니다.

마무리
긴 시간 적극적으로 참여해준 학생 여러분 모두 고생 많았고, 이 자리를 마련해주신 청주대학교 관계자분들께도 다시 한 번 감사드립니다. 앞으로도 멀티모달, 자율주행, 로보틱스 등 실전 AI 분야에서 더 재미있는 프로그램으로 찾아뵙겠습니다!
