
이전 블로그에서 로컬 pc에서 사용할 수 있는 gpt에 대해 알아봤습니다.
ollama는 상업용 언어모델이 아니라 모두가 활용 할 수 있는 오픈소스 언어모델을 쉽게 사용할 수 있게 해주는 툴입니다.
여기서는 라즈베리파이에서 ollama를 활용해서 LLM을 한 번 돌려보겠습니다. 여기서는 라즈베리파이5 4gb를 사용했습니다. 저희 자율주행 과정에서 사용되는 라파5 (라즈베리파이5) 입니다.
Ollama 설치 과정은 정말 간단한데요, Linux에 설치하려면, 터미널에 공식 설치 스크립트를 실행하면 됩니다. 이 방법은 Ollama 공식 웹사이트에서도 안내하고 있는 정식 설치 방법입니다.
그러면 자동으로 다운로드 & 설치가 시작되는데요. 한 10분정도 걸리기 때문에, 이 때 커피든 뭐든 하나 드시고 오시면 됩니다.
스크립트는 아래와 같습니다.
curl https://ollama.ai/install.sh | sh
이 스크립트는 라즈베리파이 공식 홈페이지에 들어가도 나오는 스크립트입니다.
ollama 웹페이지에 들어가게 되면 자동으로 linux를 인식하고 아래와 같은 페이지를 띄워주는데, 아래 스크립트 보이시나요? 요겁니다.
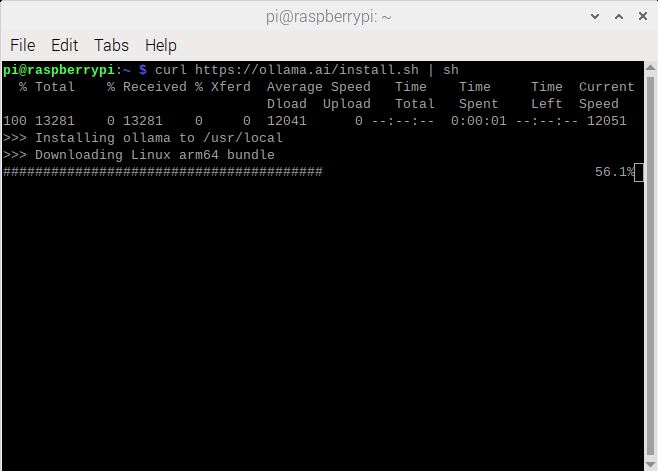
터미널에 스크립트를 입력하면 아래와 같이 설치가 시작됩니다.
<ollama 설치중>
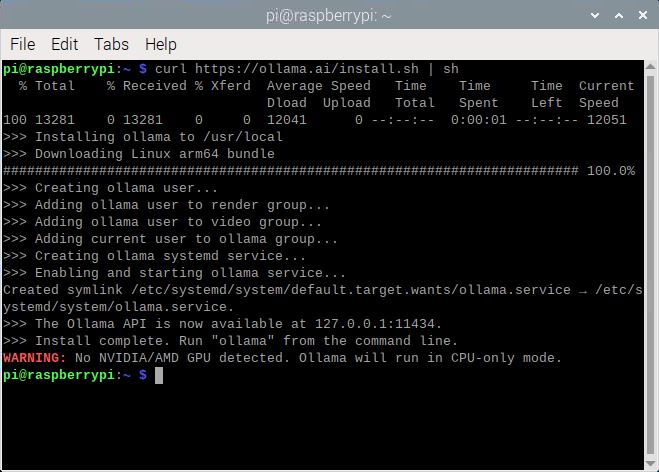
<ollama 설치 완료>
그리고 설치가 완료되면 이전 블로그에서 설명한것과 그대로 언어모델을 추가해주시면 됩니다.
언어모델은 llama 모델이나, deepseek나, gemma, mistral 등 많은데, 주의사항이 하나 있습니다.
라즈베리파이의 메모리보다 언어모델의 크기가 작아야 합니다.
즉, 7B 모델을 실행하려면 최소 8GB의 RAM이 필요하고, 13B 모델은 16GB, 33B 모델은 32GB의 RAM이 있어야 제대로 실행할 수 있습니다.
저희는 4GB 라파를 사용하기 때문에 1.5B 모델이나, 2B 또는 3B 모델을 사용하겠습니다.
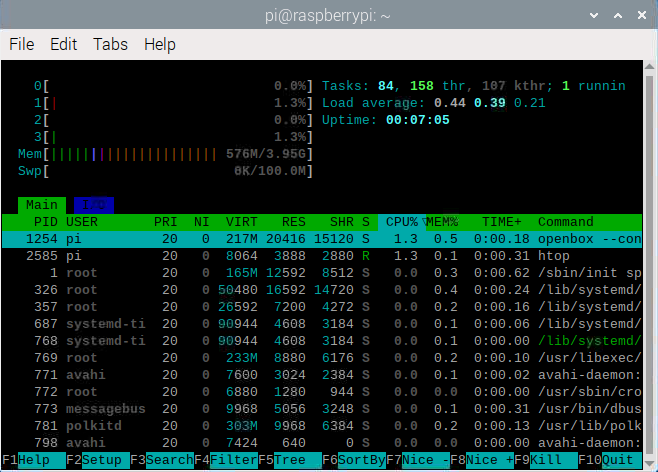
<라즈베리파이 메모리 사용량: htop 커멘드>
지난번에 이미 잘 되는 것을 확인한 llama3.2:1b 모델을 사용해 보겠습니다. 이 모델은 1.3GB로 제가 갖고 있는 라즈베리파이 4GB 메모리보다 작아서 충분히 돌아갑니다.
(3B 모델은 메모리가 3.4GB가 필요한데, 라즈베리파이가 4GB지만, 시스템 자체적으로 사용하는 메모리가 0.6~0.7GB를 사용하기때문에 이 모델을 돌리기엔 약간 부족합니다. ㅠㅠ)
설치는 아래 스크립트를 입력하면 됩니다.
ollama run llama3.2:1b
설치가 완료되면 아래와 같이 뜹니다.
혹여나 라즈베리 sd카드에 용량이 부족할 수도 있으니 "df -h" 커멘드를 통해 잔여 용량을 꼭 확인하시기 바랍니다.
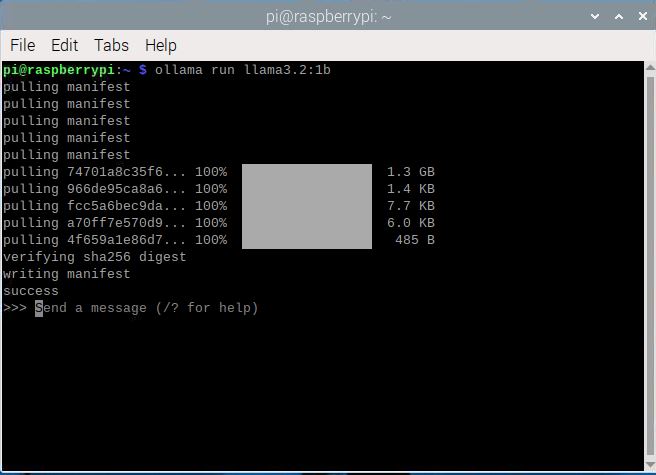
<llama3.2:1b 설치완료>
그럼이제 질문을 해볼까요?
질문은 아래와 같이 해보겠습니다.
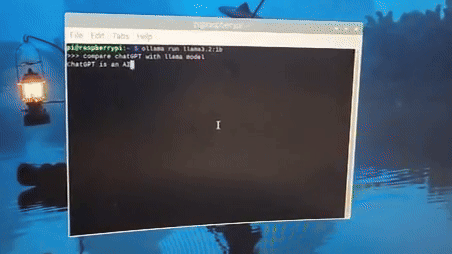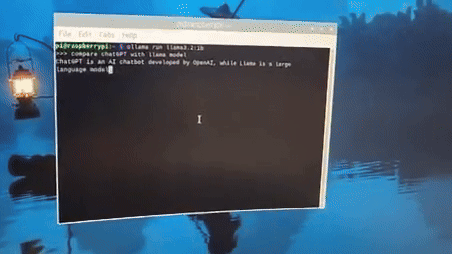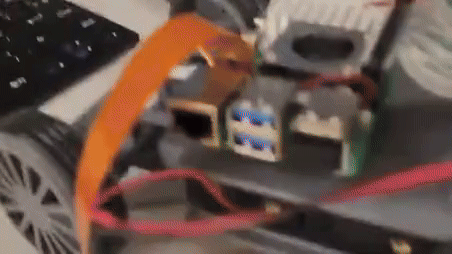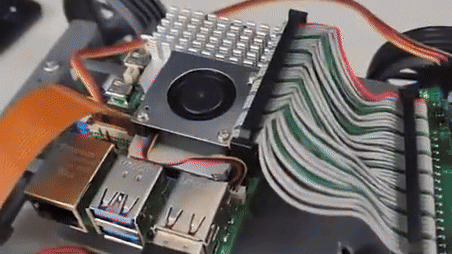
"llama 모델과, chatgpt 모델을 비교해줘"
그런데.. 이 부분은 모델이 작아서 그런지 한국어로 질문하면 엉망으로 대답해줍니다.
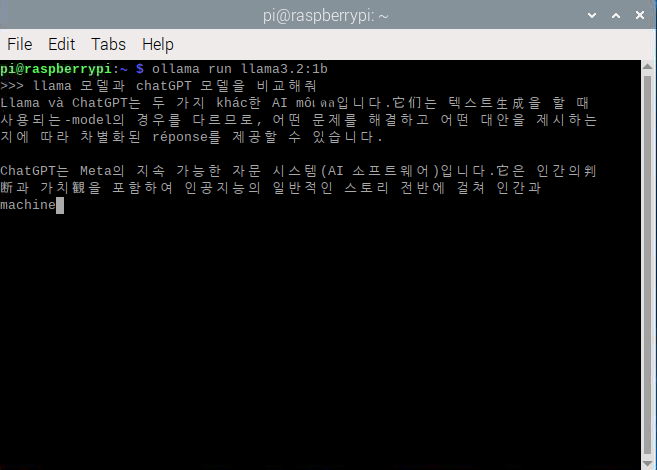
<뭐라고? chatGPT를 메타가 개발했다고!?, 이렇게 bias가 위험합니다>
대신 영어로 질문해보겠습니다.
" compare chatGPT with llama model"
아래 보이시는 것처럼, 이렇게 영어로 질문할 경우 모델이 괜찮은 답변을 내주네요.
(이렇게 개발사의 bias가 위험합니다.)
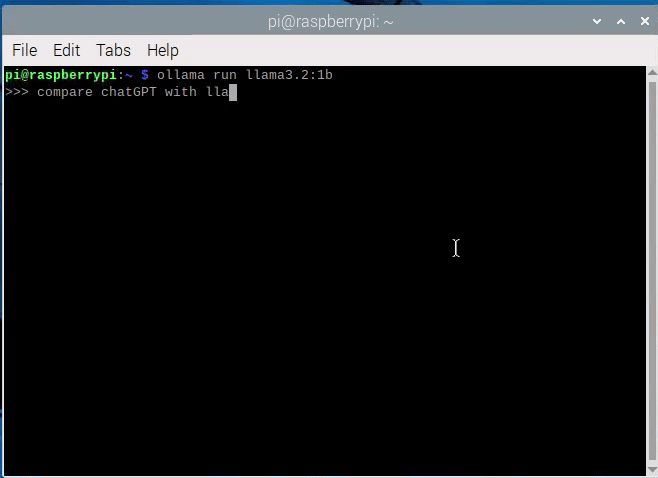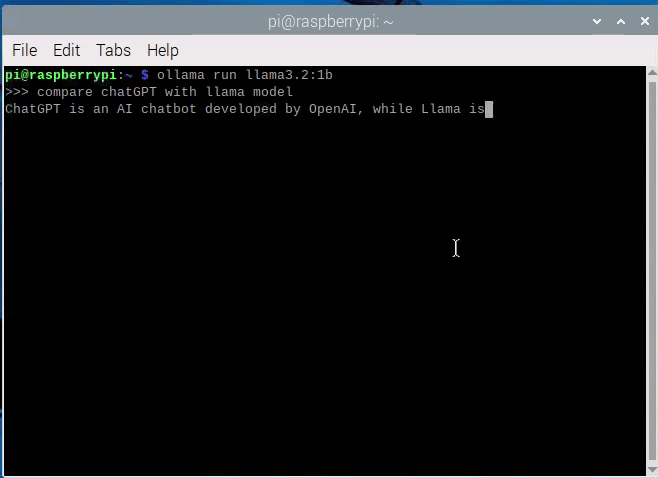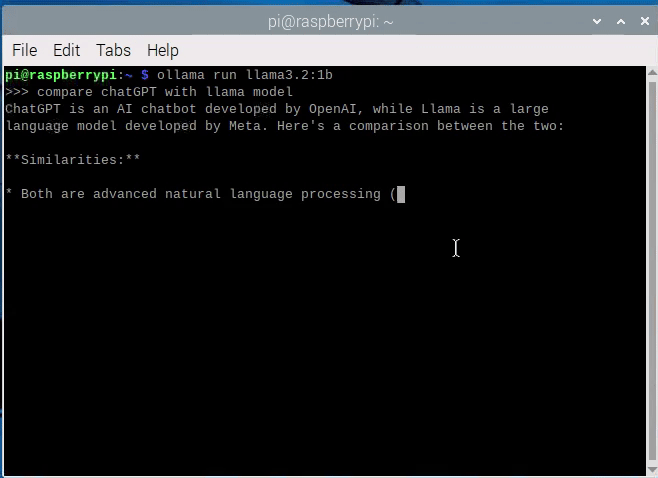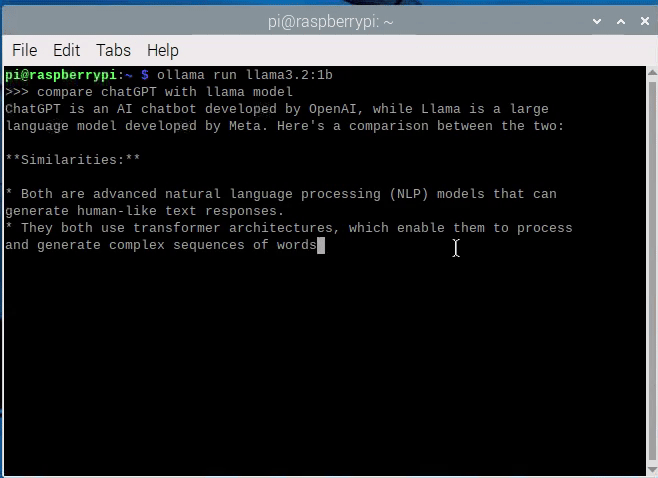
자 이렇게 마이크로 디바이스인 라파5에서 언어모델을 한 번 실행해 봤습니다. 언어모델의 발전도 눈부시지만, 이렇게 소형화 된 모델도 점점 발전하는 것 같습니다.
점점 resource가 덜 필요하면서 더 정확한 모델이 많이 나오기 시작할 것 같습니다. 소형 모델은 필연적으로 어떤 특정 언어, 더 데이터가 많은 언어 더 집중하여 학습하게 될 수 밖에 없는 것 같습니다. 따라서 한국어 성능은 아직까지는 좀 부족한 것이 느껴집니다.
조금 놀라운 것은 ollama의 실행 속도가 기대했던 것 보다 빠르다는 것입니다. 위의 질문에 커멘드창이 꽉차도록 답변하는데 10초정도 밖에 걸리지 않습니다. 앞으로 소형모델은 성능은 떨어지더라도 거의 real-time response가 가능해 질 수 있을 것으로 보이는데요. 멀기만 할 것 같은 미래가 한츰 앞으로 다가온 것 같습니다. 다음 블로그에서는 이러한 모델을 활용해서 어떻게 자율주행과 연동할 수 있는지를 알아보도록 하겠습니다.