
요즘 모두가 쓰는 chatGPT는 인터넷이 있어야 합니다. 안타깝게도 openAI에서 만든 chatGPT closed source입니다. 즉, 외부에 코드가 공개되어있지 않습니다. 그래서 제목과는 다르게, chatGPT는 못쓰지만, 구글이나, 메타에서 개발한 언어모델은 사용이 가능합니다.
chatGPT말고도 여러곳에서 open source로 언어모델을 개발했습니다. 대표적으로 meta에서 개발한 llama모델이 있고, 구글에서 만든 gemma가 있고, 일론 머스크의 xAI가 만든 grok도 처음에는 closed source였지만, 현재는 open source로 바뀌었습니다. 또 중국에서 만든 deepseek도 open source로 이용이 가능합니다.
openAI에서 만들었지만, 소스코드를 open하지 않는 것은 아이러니 한 것 같습니다. 많은 IT 플랫폼이 그렇듯, 수익을 창출하기 위해서는 어느정도의 해자가 있어야 하고, 이러한 closed source는 타 기업에 내부 구조를 공개 하지 않으면서 상용화를 하여 수익을 창출하고 있습니다. open source는 외부에 모델 구조가 공개되어있는 모델입니다. github나 hugging face같은 사이트에 모델이 올라와 있으면 일반적으로 open source로 봅니다. 내부 코드를 보거나, 최소한 모델의 아키텍쳐를 볼 수 있기 때문이죠. 아래는 ollama 사용 예제입니다. 뭔가 UI가 클래식 하죠?
여기서는 ollama를 활용해서 로컬에서 개인용 gpt를 사용해 보겠습니다.
<ollama 사용 예제>
ollama는 이런 공개된 모델을 여러분들의 컴퓨터에서, 즉, 로컬에서 이러한 언어모델을 쉽게 다운받고 실행 시킬 수 있는 오픈소스 프로그램입니다. 이번 블로그에서는 ollama를 활용해서 아주 쉽게 이런 llama 모델, deepseek 모델을 활용하는 방법을 알려드리겠습니다. ^^
다른 open source언어모델도 활용이 가능합니다. 혹시 여러분이 raspberry pi같은 마이크로 디바이스를 사용하게 된다면, 여기에도 소형 언어모델을 로컬로 받아서 활용 할 수 있습니다.
ollama 다운로드
우선 ollama를 다운 받아 보겠습니다. 1gb정도 되는 설치파일 입니다. 구글에서 ollama를 검색해서 가장 상단에 나오는 링크를 클릭하거나, 여기를 클릭하시면 다운로드 할 수 있는 페이지가 나옵니다.
저기 보이는 다운로드 버튼을 클릭하면 설치파일이 다운됩니다.
다운이 완료되면 exe파일을 클릭하시면 설치가 진행됩니다. 설치가 바로 진행되는데 따로 설정할 것은 없습니다.
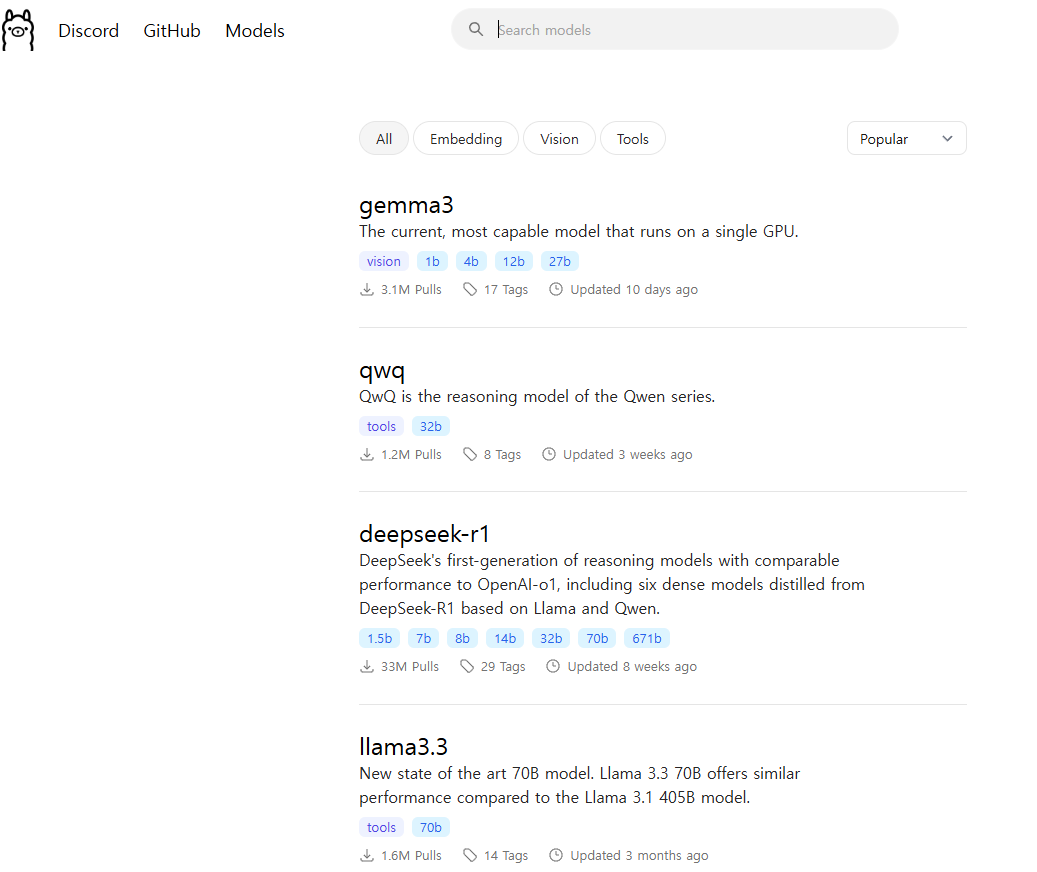
설치가 완료되면, 어떤 언어모델을 사용할지를 골라야 합니다. ollama 메인페이지에서 models를 클릭하거나 여기를 클릭하면 사용가능한 모델이 여러개가 뜹니다. 가장 위에 gemma3와 또 deepseek, llama 모델이 뜨네요. qwq모델은 알리바바에서 만든 추론 (문제풀이) 전용 모델입니다. 중국의 AI발전이 눈부십니다. 우리나라도 빨리 이렇게 발전했으면 하는 바람이 있네요.
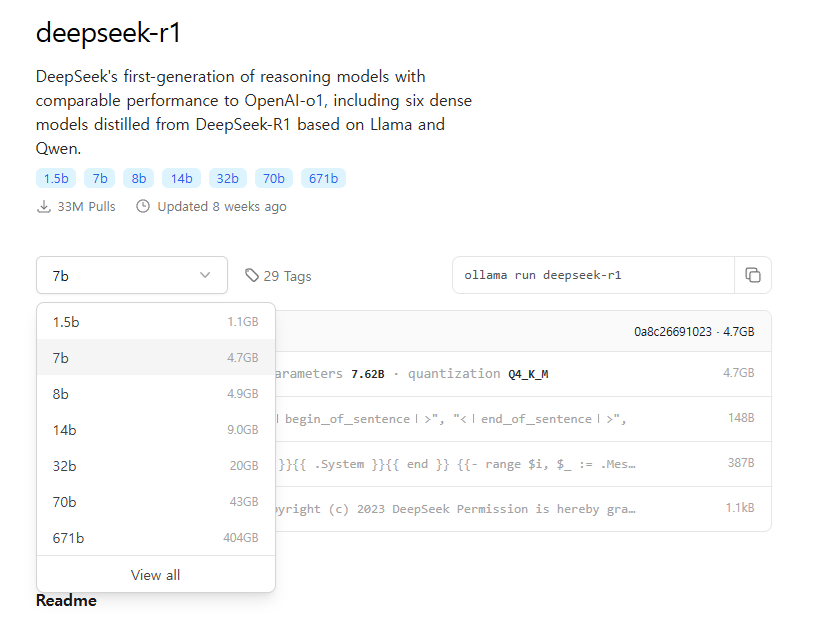
저는 deepseek 모델을 활용해보겠습니다. deepseek-r1을 클릭해줍니다. 혹은 여기를 클릭해줍니다.
모델의 크기를 고를 수 있는 드롭다운 박스와, 오른쪽에 ollama run deepseek-r1이라고 써져 있습니다. 같은 모델 아키텍쳐라도 여러 사이즈로 나옵니다. 아주 작은 사이즈(1.1gb)부터, 큰 사이즈(404gb)까지 다양한 크기의 언어모델을 사용 할 수 있습니다. 언어모델은 모델의 크기, 즉 파라미터가 많을 수록 일반적으로 더 정확한 답변을 해줍니다. 더 다양한 상황에 대응 할 수 있게 되죠. 그런데 모델의 크기를 키우게 되면, 더 많은 메모리와 리소스를 요구하게 되고, 결국 AI 개발 비용으로 이어집니다. 또 너무 큰 모델은 일반 pc에서 실행도 불가능 합니다.
deekseek-r1 모델에서 가장 작은 모델은 1.5b입니다. 1.1gb 밖에 하지 않아서 언어모델 치고는 아주 작고, 성능은 우수한 편이 아닙니다. 특히나 한국어로 된 질문이나, 답변을 잘 하지 못합니다. 아무리 많이 학습을 하더라도, 모델 파라미터가 작으면 질문에 대응할 수 있는 능력에 한계가 있습니다.
모델의 크기는 여러분의 pc 사양에 맞게 한 번 찾아보시기 바랍니다. 저는 14b 모델을 받아서 한 번 해보도록 하겠습니다.
언어모델 다운로드
ollama는 언어모델을 실행하기 위한 플랫폼이고, 이 ollama에서 언어모델을 사용하기 위해서는 언어 모델을 따로 다운받아야 합니다. 여기서는 deepseek 모델중에서 14b 모델을 다운받아 보겠습니다. 여러분은 다른 모델도 나중에 함께 받아서 사용해 보세요.
위의 화면에서 오른쪽에 7b로 되어있는 것을 14b로 변경하여 클릭하면 옆에 ollama run deepseek-r1 이 부분이 ollama run deepseek-r1:14b로 변경됩니다. 그러면 이걸 복사해서 여러분 컴퓨터의 cmd창에 입력을 해보겠습니다. 윈도우에서는 시작-cmd를 검색하면 켤 수 있습니다. 그리고 cmd에 "ollama run deepseek-r1:14b"를 입력하면 모델 다운로드가 시작됩니다.
9gb 짜리 모델이라 10분이나 걸리네요. 기다려 보겠습니다.
<deepseek-r1 모델 다운로드>
<deepseek-r1 모델 다운로드>
설치가 완료되면 자동으로 실행이 됩니다.
커멘드창에 질문을 입력하면 답변을 해줍니다.
그리고 한 번 설치된 모델은 cmd창을 끄더라도, 다시 cmd창을 켜서 "ollama run deepseek-r1:14b"를 입력해주면, 다운받았던 모델을 바로 실행시켜줍니다. 다시 언어모델을 다운 받을 필요가 없습니다. 다운받은 언어모델은 여러분의 pc에 저장됩니다.
성능 테스트를 해보기 위해 다음 질문을 던져보겠습니다.
"언어모델과 성능에 대해 알려줘"
이 질문의 정답은 "모델이 커질수록 성능이 좋아진다" , "그럼에도 모델 아키텍쳐에 따라 달라질 수 있다" 입니다.
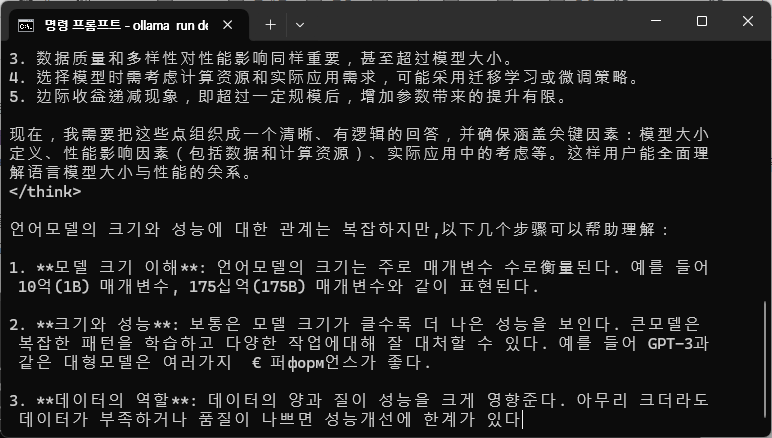
<deepseek r1 14b 모델 답변, 중국어와 한국어가 번갈아가면서 쓰이지만, 내용적인 측면에서는 얼추 맞는 답변을 해준다.>
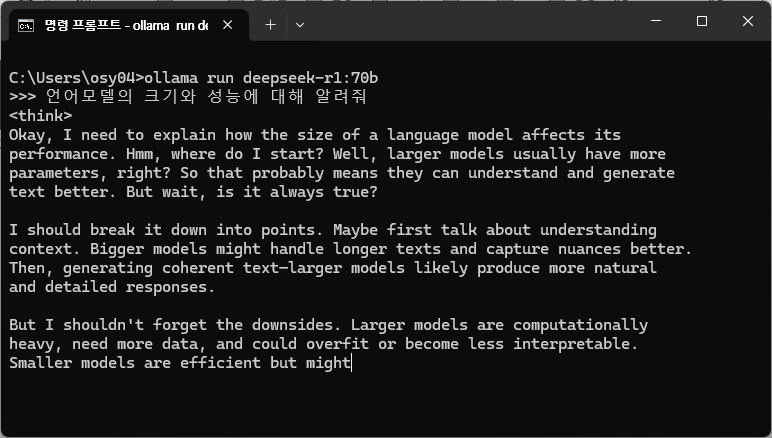
<deepseek r1 70b 모델 답변. 많은 질문을 해본 것은 아니지만, 신기하게도 항상 답변을 okay,로 시작한다.>
중국산 모델이라 그런지, 중국어로 먼저 대답을 하고 나중에 한국어로 대답을 해줍니다. 한국어 답변의 경우 한국어와 중국어가 섞여있는 혼란스러운 모습을 보이고, 가끔씩 일본어도 섞어서 답변을 해줍니다. 어쩔 수 없이 학습 과정에서 중국어 학습 데이터가 많기 때문에 중국어 위주의 답변이 나올 수 밖에 없도록 편향(bias)가 발생한 것으로 볼 수 있습니다. 보면서 더더욱 경량화된 한국어 위주의 모델이 ollama에도 배포되었으면 하는 바람이 생기네요. 그러면 작은 모델이지만 많은 곳에 활용이 가능해 질 것 같습니다.
14b 모델도 작은 모델은 아니지만, 상업용 언어모델의 경우 수백기가 모델이 일반적으로 사용되고 있습니다. 비교해보면 14b 모델은 상대적으로 미니 사이즈라고 볼 수 있습니다. 그럼 70b 모델은 어떨까요? 크기가 5배 정도 되는 모델은 더 나은 답변을 해줄 수 있을 것으로 기대해 보았지만, 70b 모델도 다운받아 실행 해본 결과, 영어 또는 중국어부터 답변해줍니다. 다양한 언어에 대한 대응력이 부족한 것이 deepseek 초기버전의 한계점을 잘 보여주는 것 같습니다. (저도 나름 큰 메모리를 갖고 있다고 자부하고 있었는데 가장 큰 모델인 404gb 모델은 시도도 못해봤습니다. ㅠㅠ)
ollama의 장점중 하나는, 모델이 크더라도, RAM 사이즈만 크면 어느정도 돌아갈 수 있게 설계되었습니다. 20gb 짜리 모델은 일반적으로 20gb의 VRAM, 즉, 그래픽카드 메모리가 필요한데, 일반적인 사용자가 20gb VRAM을 갖고 있기가 어렵습니다. 그래서 대신 시스템 메모리인 RAM를 사용하여 실행하게 됩니다. (대신 cpu를 활용하면서 답변이 느려집니다.) 즉, 그래픽카드에 모델을 담아서 돌리는 것이 아니라 RAM에 모델을 담아서 돌리게 됩니다. 따라서 모델 크기보다 RAM이 크기만 하면, 모델이 실행 됩니다. 반대로 모델이 RAM보다 크면, 실행이 되지 않습니다.

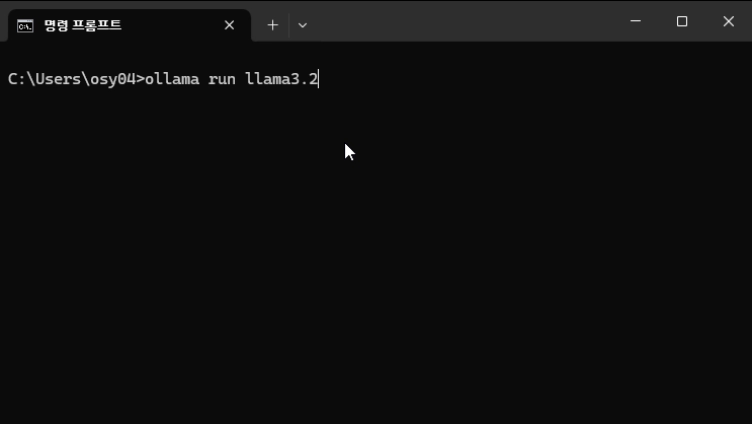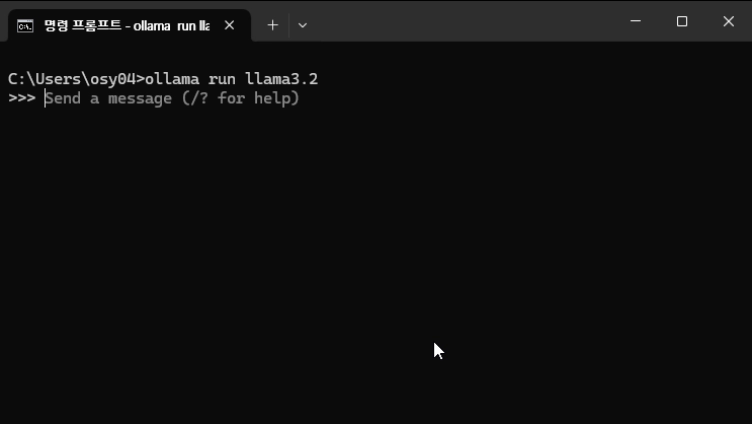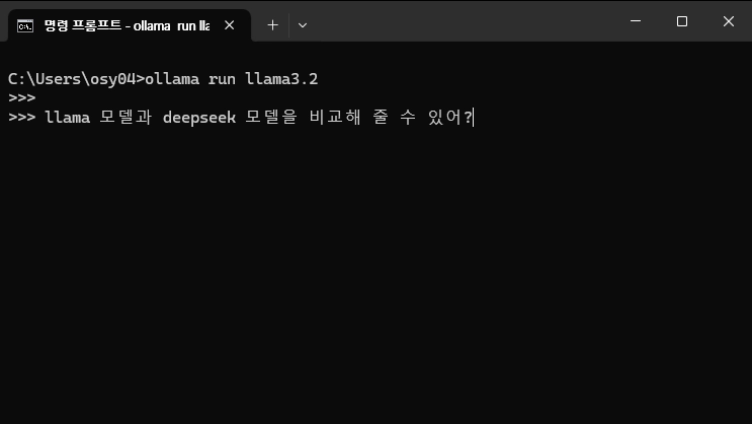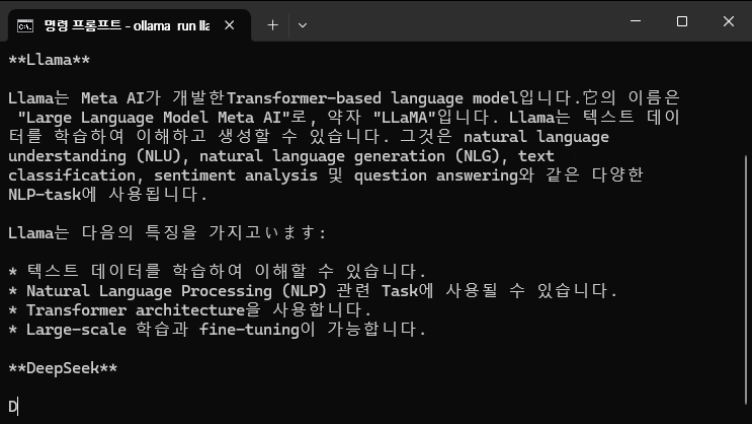
생각보다 실망스러운 한국어 성능의 deepseek-r1의 모델을 뒤로하고, 그렇다면 meta의 llama 모델은 어떨까요? 이 모델도 한 번 받아서 확인해보겠습니다. meta의 llama3.3 70b모델의 경우 모델이 여러 언어에 특화되어있다고 합니다. 반면, 참고로 70b 모델은 40기가 정도 되는 모델입니다. 위에 표에서도 보여주는데, 놀랍게도 이런 40gb 짜리 모델이 GPT-4o에 필적하는 벤치마크 성능을 보여준다고 설명하고 있습니다. 이 모델도 다운받아서 한 번 해보도록 하겠습니다. 모델 링크는 여기서 확인해 보면 됩니다.
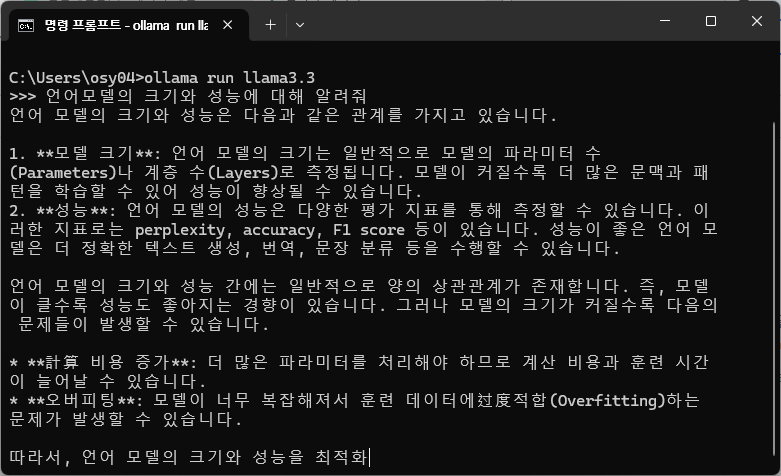
<llama 3.3 70b 모델>
llama 3.3의 경우 한국어 질문에 대해 한국어로 답변도 해주고, 답변 자체도 퀄리티 있는 답변이 나옵니다. "모델이 커질수록 더 많은 문맥과 패턴을 학습할 수 있어 성능이 향상될 수 있음" 답변과 모델이 커졌을 때의 문제점을 잘 설명하는 것으로 나타납니다. 중간중간에 "계산 비용" 대신 "計算 비용"을 사용하지만, 한국어 답변이 우수한 것으로 보입니다. 전반적으로 모델 성능이 meta에서 설명한대로 여러 언어에 대한 대응이 잘 되는 것으로 보이는데, deepseek r1 보다 더 나은 결과로 보여집니다.
단, 모델 사이즈가 커지면서, 시스템 메모리를 사용하고, 시스템 메모리를 사용하면서 gpu 보다는 cpu 사용량이 늘어나게 되는데, 이로 인해 모델 실행 속도는 크게 감소하게 됩니다.
이참에 meta의 llama3.2:3b 모델도 받아서 같은 질문을 던져보겠습니다. 2gb 정도되는 경량화 모델입니다. 경량화 모델은 답변의 퀄리티는 낮더라도, 질문에 훨씬 빠르게 답해줍니다. 목적에 따라 정확한 답변이 필요한 곳이 아니라면 충분히 여러곳에 활용이 가능합니다.
설치는 cmd에 "ollama run llama3.2:3b"를 입력하면 됩니다.
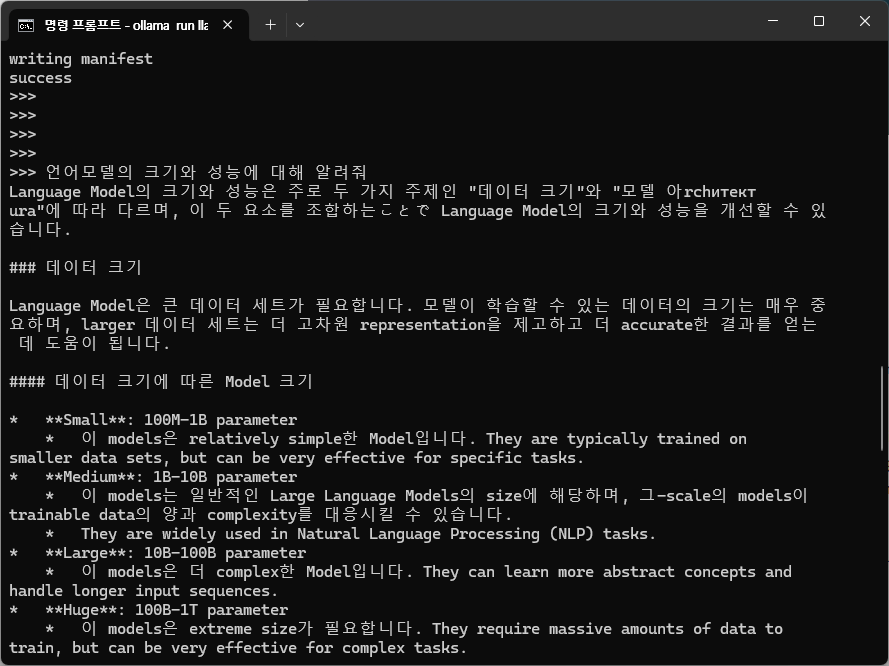
<llama 3.2 3B 모델>
llama 모델은 놀랍게도, 작은 모델임에도 deepseek r1에 비해 한국어로 답변해주려는 경향이 더 강합니다. 경량화 모델이라서 답변의 퀄리티는 떨어질 수 있으나, 이해 가능한 수준입니다. 미국산 모델이라 그런지 영어를 많이 쓰는 것으로 나타납니다. 하지만 학습 데이터의 대부분이 영어 데이터로 되어있어, 이런 소형 모델에서는 아직까지는 어쩔 수 없어 보입니다. 사이즈가 작아서 이 모델은 raspberrypi에서도 돌아갈 수 있을 것으로 보입니다. 다음 블로그에서는 raspberry pi에서 로컬 환경으로 언어모델을 실행해 보도록 하겠습니다.
모델 위치
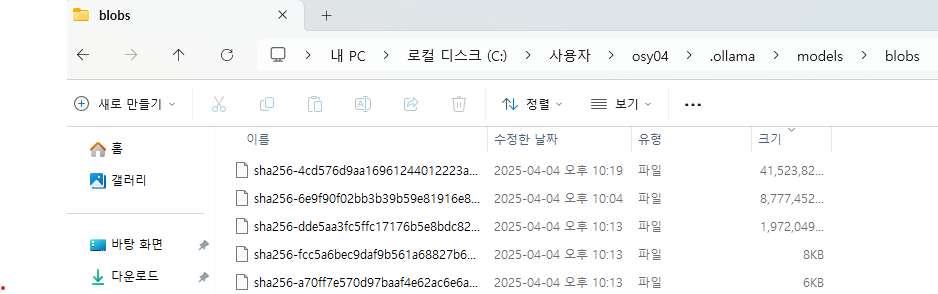
이렇게 다운받은 모델은 여러분의 pc에 저장됩니다. 일반적으로 저장되는 위치는
C:\Users\<사용자 이름>\.ollama\models
입니다. 용량이 부족해서 모델 삭제가 필요할 경우 여기서 blobs 폴더를 삭제해주면 됩니다.
결론
- ollama를 통해 로컬에서 opensource 언어모델을 활용 할 수 있습니다.
- deepseek-r1의 14b, 70b 모델은 중국어나 영어 답변 비중이 높고, 기대만큼의 성능을 보여주지 못하고 있습니다.
- 반면, llama 3.3 70b 모델의 경우 multi-lingual 패치가 되어서 한국어 성능도 잘 나오는 것으로 보입니다.
- 이런 llama 모델은 2gb짜리 경량화 모델도 존재합니다. 성능은 떨어지나 마이크로 디바이스에서 활용할 때 유용 하게 활용 할 수 있습니다.